
當「民調邏輯」誤入「B2B地獄區」:客戶將面臨的五大決策災難
【30秒精選摘要】
- 方法錯置的風險:用B2C民調思維(隨機抽樣)去調查B2B市場,就像用「一人一票」去決定商業決策,會導致大客戶(大象)的聲音被小客戶(螞蟻)淹沒。
- 數據的虛胖陷阱:未經清洗的樣本清冊會製造出「不存在的市場」(如32.5億的虛假規模),唯有透過資料庫篩選,才能還原真實的「可服務市場」(14.9 億)。
- 拒訪率的黑盒子:一般民調遇到拒訪習慣「打下一家」,導致「資格不符」的無效名單被隱藏;B2B調查必須「窮盡查證」,才能算出名單的真實含金量。
【本文金句】
- 『 隨機抽樣的本質缺陷,是將「黃金」與「沙子」混為一談。』
- 『 在地獄區,統計顯著性往往只代表「家數多」,絕不代表「產值高」。』
- 『 最大的風險不是調查執行得不夠完美,而是用錯了尺去量世界。』
前言:方法論的誤用,是決策錯誤的開始
在市場研究中,最危險的不是「不知道」,而是「知道了錯誤的答案」。
許多企業主習慣用B2C的民調思維來檢視B2B市場:『 給我一份符合統計抽樣分析的報告,告訴我市場平均狀況 』,這在客戶均質的「統計區」(如防毒軟體、消費品)是有效的。
但在高度離散、需求分歧的「B2B地獄區」(如工業設備、食品加工),這種思維會引發一場災難(你的客戶年均貢獻差異很大)。這裡的客戶結構呈現極端的雙峰分佈,大客戶與小客戶是完全不同的物種。如果堅持在此區域使用一般民調方式,客戶將面臨五大決策問題。以下我們逐一拆解這些陷阱。
災難一,隨機性的迷思:「一視同仁」會讓你錯失關鍵商機
The Myth of Randomness: Missing the Critical Opportunities
隨機抽樣的本質缺陷:將「黃金」與「沙子」混為一談。
很多人常認為:『 隨機抽樣最公平,能客觀反映市場全貌。』
這在均質市場是對的,但實務上這樣的場景很少,最具有代表性的大概就是選舉民調,一人一票。
但在B2B地獄區或說多數的B2市場,市場是極度不均質(Heterogeneous)的。
試想,一個市場中,前5%的客戶(大象)貢獻了80%的營收,剩下95%的客戶(螞蟻)只貢獻20%。如果你堅持「隨機抽樣」,你的樣本結構會忠實反映母體數量。
『 也就是抽到95隻螞蟻和5隻大象。這在統計上是正確的,但在商業上是致命的。』
對企業而言,這會產生嚴重的誤區:當你在看數據分析時,很容易得到一個「客單價過低」的結論,不論是單純的平均數、中位數計算,或是其他統計檢定。你的關鍵商機會被大量的低價值樣本(95%的螞蟻)混入分析時,產生巨大的「稀釋效應(Dilution Effect)」。
解法:事實上,你一開始就需要放棄「完全的隨機性」,必須要把調查對象分為兩類:
- 針對高價值區(大象): 放棄抽樣,進行全查。這是不同的商機區域,需要用顧問式訪談挖掘深層需求。
- 針對低價值區(螞蟻): 才使用抽樣調查,確認覆蓋率即可。
唯有打破隨機性,區別對待不同商機,才能讓數據服務於戰略。
災難二,樣本清冊的迷思:虛胖的母體,製造了「不存在的市場」
The Myth of Sampling Frame: TAM vs. SAM
我們常告訴客戶,因為我們有完整的企業資料庫,所以可以提供更好的B2B產業調查。當然,我知道90%的客戶都不在意這件事,認為怎麼蒐集名單是調查公司的事,甚至覺得我們因此收費較貴是「報高價」的策略。
但事實上,在釐清大象跟螞蟻的問題後,讓我們來看一下樣本清冊數量的問題。
假設台灣食品登記公司有15,000家,客戶一定會認為這就是目標客戶,後續再依據這個數字去推估。就像下表所示,你會得到一個過度高估的市場(32.5 億),而且你不知道對象是誰,業務該去找哪些公司。
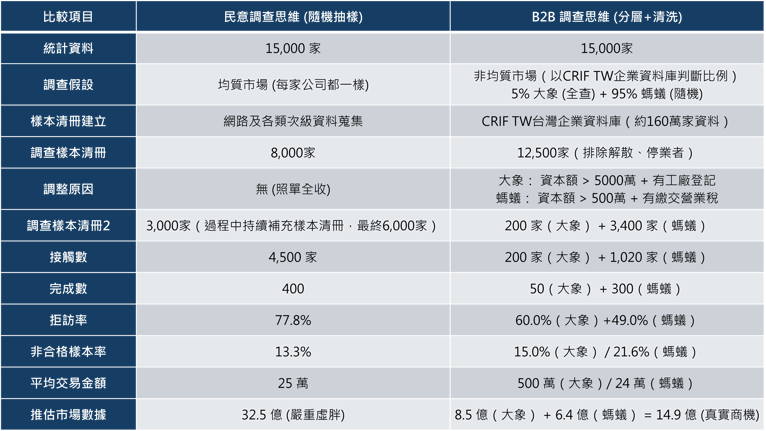
在我們的處理中,就像上表一樣,你會看到我們要做一些篩選,避免客戶被「不存在的目標客戶」給迷惑了。我們需要排除:
- 已經倒閉的公司(這是黃頁或Google上最容易發生的事情)。
- 沒有在營運的公司(查不到繳營業稅的資料)。
- 規模過小或非核心業務的公司(資本額過小或是食品不屬於核心業務)。
透過完整的企業資料庫篩選,你會發現市場上根本沒有15,000家食品業可買設備。但同時,你可以拿到所有大象(200家)跟螞蟻(3400家)的精準名單。不論是要讓業務進行一對一拜訪(大象),或是針對廣大潛在客戶進行廣告推廣(螞蟻),你都會有清楚的面貌去操作。
災難三:拒訪率的迷思——無法區分「沈默」與「資格不符」
The Myth of Refusal Rate: Non-response vs. Ineligibility
承接上表,當我們看到民調思維下的「拒訪率77.8%」時,這是一個混雜了各種原因的黑盒子。在一般民調中,這通常被解讀為「執行不力」或「受訪意願低」。但在B2B地獄區,這個數字裡藏著兩個截然不同的訊號,若不區分,將導致嚴重的行銷資源錯置。
這兩個訊號分別是:
- 無回應誤差(Non-response): 對方是合格買家(大象或螞蟻),但太忙不接電話。
→ 這是統計偏差,需要設法追回。 - 資格不符(Ineligibility): 對方接了,但告知「我們沒工廠」或「都找代工」。
→ 這是市場邊界,需要剔除。
民調與 B2B 在操作上的決定性差異:這是一個基本思維,看似民調與 B2B 調查都會做類似的篩選,但在實際操作上,判定標準卻天差地遠
- 民調執行邏輯(打下一家就好):
由於假設是均質市場且強調隨機抽樣,樣本來源似乎無窮無盡。當遇到拒訪或模糊不清的狀況時,執行人員傾向直接「打下一家」。這導致許多的「資格不符」被隱藏在龐大的「無回應誤差」中,反正只要湊滿樣本數即可,沒人深究分母的純度。 - B2B 調查執行邏輯(窮盡查證):
樣本清冊是有限的(大象可能只有 200 隻),我們不能輕易放棄任何一個名單。因此,判定標準極為嚴格:
- 關於無回應: 我們必須設下黃金標準(如:一週接觸三次,不同時段),三次都被拒絕,才敢歸類為「無回應誤差」。
- 關於資格不符: 因為我們擁有企業資料庫,當受訪者說「資格不符(沒工廠)」時,我們不會輕易採信。我們會反查資料庫:「但資料庫顯示貴公司有工廠登記,請問目前的登記工廠是生產什麼東西?」
我們需要花更多時間去「質疑」與「確認」受訪者的回覆,才能將趨近真實的「無回應」與「資格不符」辨識出來。透過這樣的辨識,我們才可以幫客戶提供兩個關鍵數據:
- 校正後的真實市場母體(Corrected Market Population): 剔除資格不符後,確認市場上真正存在的買家只有1,000家,而非名單上的5,000家。
- 行銷名單的「含金率」: 告訴客戶,您手上的名單只有20%是有效的。未來的行銷預算應該集中火力在這 20% 上,而不是對著 100% 的名單亂槍打鳥。
災難四:統計檢定的迷思——平均值的死亡與「大數暴力」的誤導
The Myth of Statistical Significance: When Ants Drown out Elephants
傳統統計檢定(如 Chi-square, t-test)不僅依賴常態分佈假設,更危險的是它們天生傾向於「獎勵數量(N值)」。在地獄區,這會導致「數量多的小客戶」在統計上完全掩蓋了「數量少的大客戶」。
客戶面臨的決策災難:被「螞蟻雄兵」綁架的戰略地圖
舉一個最血淋淋的例子:「區域優先序的誤判」。假設我們要做「業務據點佈局」的決策檢定:
- 台北(螞蟻窩):有500家小型食品貿易商(員工人數 < 5人)。
- 雲嘉南(大象群):只有50家大型食品加工廠(員工人數 > 200人)。
如果您使用標準的統計檢定跑「區域 vs. 採購意願」:
由於台北樣本數高達500(N=500),統計軟體會跑出極為顯著的P-value,告訴您:「台北是顯著的熱區,應優先佈局。」反之,雲嘉南因為N值小,可能跑不出顯著性。
這樣的檢定結果,可能會促使企業把80% 的業務大軍派駐到台北,每天勤奮地拜訪那些年採購額只有5萬的小公司。而那50家年採購額5億的大廠,因為在統計上「不顯著」,被晾在南部沒人理。
這就是「大數暴力」。在B2B地獄區,統計顯著性往往代表的只是「家數多」,而不是「產值高」。如果不進行加權或分層檢定,統計學就會成為誤導戰略的幫兇。
災難五:決策邏輯的迷思——問「事實」只會得到假資料,你需要「質化校正」
The Myth of Fact-Finding: Why Qualitative Research is Mandatory
最後一個陷阱在於:我們太迷信問卷能問出「真相」。
在B2B設備市場,採購週期長達10-15年。現在的受訪者(廠務/採購),10年前可能還沒進公司。如果您在問卷中問:『 貴公司上次採購金額是多少?規格是什麼?』,您得到的往往是模糊的印象或不可信的猜測。
客戶面臨的決策災難:基於「模糊記憶」的精確預測
如果您拿這些充滿「回憶偏誤(Recall Bias)」的數據進模型跑預測,您只是在做「垃圾進,垃圾出(GIGO)」。您算出的市佔率,都是建立在受訪者的「我猜好像是…」之上。
正確的調查思維:從「問歷史」轉向「問模型」,並引入質化研究
1. 改問「採購決策模式」:可以問不可考的歷史金額,但更要問「未來的權重」:
- 『 如果明天要買,技術佔分多少?價格佔分多少?』
- 『 是廠長決定,還是總公司採購決定?』這些「邏輯」通常比「記憶」更穩定、更可靠。
2. 為什麼B2B調查一定包含「質化研究」?這就是為什麼我們的B2B專案裡,幾乎都標配了「深度訪談(IDIs)」。質化研究在這裡不是為了「聽故事」,而是為了「校正數據的準星」。
- 當問卷數據顯示「A品牌市佔率30%」,但質化訪談中5位大廠廠長都說『A品牌很爛,我們早就不敢用了 』。
- 當問卷數據顯示「平均採購金額是20萬」,但質化訪談中3位SI 業務都說『小公司一年大概都花15萬』。
這時候,我們要將質化當作一個權重,去分析跟調整量化的結果。因為問卷可能被幾百家沒經驗的小廠給稀釋了。
在地獄區,量化數據提供的是「廣度」(覆蓋率),但只有質化研究能提供「精度」(決策邏輯)。缺少質化校正的B2B調查,就像沒有準星的槍,子彈再多也打不中靶心。
結語:用「商機思維」取代「民調思維」
總結來說,當您身處B2B地獄區時,最大的風險不是調查執行得不夠完美,而是用錯了尺去量世界。
- 隨機性會讓螞蟻淹沒大象,稀釋您的關鍵商機。
- 未清洗的樣本清冊會製造巨大的市場泡沫(32.5億 vs 14.9億),讓您追逐不存在的幻影。
- 錯誤的平均值會誤導您的定價策略,讓產品在市場中兩頭落空。
唯有意識到這些統計學在商業應用上的侷限,採用分層、清洗、區隔的B2B調查思維,您才能穿透數據的雜訊,找到那條通往真實商機的路徑。
▲本文轉載自Nickolas商業解謎思
﹊﹊﹊﹊﹊﹊
CRIF觀點
作者在〈B2B市場研究悖論2:當「民調邏輯」誤入B2B地獄區的五大決策災難〉中點出一個核心事實:一旦把B2C選舉民調的思維,硬套在高度不均質的B2B市場上,得到的不是洞察,而是被數字美化過的錯誤判斷。
從CRIF在台灣B2B案子的經驗來看,這篇文章談的不是技術細節,而是會直接影響「人怎麼派、預算怎麼燒、策略怎麼選」的實戰問題——你到底是在看清市場,還是在被自己做出來的統計結果催眠。
一、在B2B裡,不是「一人一票」,而是「貢獻度愈高票愈多」
文章用「大象 vs 螞蟻」說明隨機抽樣的盲點:前5%的客戶貢獻80%的營收,剩下95%的客戶只貢獻20%。在這種結構下,「隨機抽樣」會忠實反映數量,但商業決策真正需要的是「價值加權」。
CRIF在很多案子裡看到的情形是:
- 問卷可能收集了300份以上,看起來樣本數充足且統計顯著。
- 但這300份裡,幾乎沒有一間企業是年採購額上億的關鍵客戶,清一色是「螞蟻型」的小客戶。
結果是:
- 統計告訴你「平均客單價很低」、「大家價格很敏感」、「南部需求看起來不大」;
- 現實是,你忽略了少數那幾家一口氣就能吃掉你半條產線的大型客戶。
CRIF的立場是:在B2B地獄區裡,「樣本代表性」的衡量標準,應該是「這批樣本合計掌握的營收權重有多高」,而不是「n值有多大」。
因此在高價值客戶群(大象)上,我們從不談「抽樣」,只有「全數列管、逐一訪談」這個選項。
二、名單不乾淨,所有後面算出來的「市場規模」都是幻覺
文章用食品業的例子,對比了「登記上有15,000家」與經過data clean後「真實可服務市場約14.9億」的差異,這段描述與CRIF實際操作高度一致。
在CRIF的做法中,真正花時間的是「拆掉客戶自備名單,重新建模」這一步,而不是直接進入訪談或發問卷。
我們至少會做三件事:
- 剔除根本不存在或已失效的企業
包含已解散、停業、無營業稅紀錄的公司,這些在公開名錄或黃頁裡非常常見。 - 排除與目標市場無關的公司
例如登記有食品類別,實際主業卻是貿易或其他服務,對設備商而言並非真正的設備採購者。 - 按照規模與產能,做出「大象 vs 螞蟻」的分層
透過資本額、產線、工廠登記等資訊,把真正有能力大量採購設備的大客戶(大象)與大量但貢獻有限的小客戶(螞蟻)分開;這一步會直接影響後續訪談策略與市場規模推估。
結論很直接:
如果母體名單是虛胖的,任何TAM/SAM/SOM的推估,都是在拿沙子當金礦秤重。
三、拒訪不是「執行爛」,常常是在提醒你「市場根本沒那麼大」
文章談到「拒訪率的黑盒子」,把「無回應」與「資格不符」清楚分開來,這一點在B2B研究裡極其關鍵。
在一般民調裡,打不通或被拒訪,訪員多半會「打下一家」,只要樣本數湊齊就好,分母的純度較少被質疑。
但在B2B地獄區,名單是有限的,且很多公司實際上沒有採購資格,因此CRIF的基本原則是:
- 對於「無回應」的名單,按照調查流程及接觸標準,我們會設定明確的追訪標準(例如不同時段多次嘗試),確認對方真的是忙、不方便,而不是系統性排斥。
- 對於「自稱資格不符」的名單(例如說「沒工廠」、「全外包」),我們不會直接接受,而是回頭對照CRIF的企業資料,進一步確認登記與實際營運狀況。
這種「窮盡查證」的目的是:
- 算出「校正後的真實母體數」——例如名義上有5,000家,實際有效只有1,000家;
- 算出現在這份名單的「含金率」——例如你手上2,000筆名單,真正值得業務花力氣追的,可能只有400家。
從CRIF的角度看,拒訪率高有時候不是壞事,它其實在提醒你: 你以為的市場範圍,是被虛假的名單撐大了。
四、沒有質化校正的量化數字,只是一堆沒有準星的子彈
文章最後談到「問歷史」往往只會問出模糊記憶,而質化訪談的角色是用來「校正量化準星」,這與CRIF的實務操作高度吻合。
在設備採購週期長達10–15年的產業裡,今天負責採購的人,十年前可能還沒進公司。
如果問卷問的是「上次買多少錢、買什麼規格」,答案多半是猜測。
因此在CRIF的設計邏輯裡:
- 問卷重點會放在未來的決策模式與評估權重(誰決定、看什麼、怎麼評價廠商),而不是執著於過去的精確金額。
- 同時,我們會把深度訪談視為必要配備,而不是「可有可無的故事補充」。當量化結果與大客戶或SI的敘述明顯不一致時,我們會優先相信這些高權重樣本的觀點,並回頭調整對量化數據的解讀。
簡單說: 在B2B地獄區,量化提供的是「覆蓋率」,質化提供的是「方向與權重」。少了質化校正的量化數據,只會讓你更快、更用力地往錯的方向衝。
結語:CRIF在B2B地獄區堅持的三條底線
綜合這篇悖論2的重點以及CRIF的實戰經驗,李俊協理在B2B市場研究上,有三條不退讓的底線:
- 大象不談抽樣,只談全覆蓋。對高價值客戶,必須個別對待、逐一理解,不能讓他們被95%的小樣本統計稀釋掉。
- 名單不乾淨,寧願不算市場規模。在母體結構不被釐清之前,任何「幾十億市場」的推算都只是漂亮的幻覺。
- 量化結果若與關鍵客戶的深度訪談嚴重矛盾,不能直接寫進結論。數字必須為決策服務,而不是為表格服務;CRIF會用質化去校正量化,而不是相反。
在B2B地獄區,企業真正需要的,不是一份「看起來統計很完整」的民調報告,而是一份能幫你看穿螞蟻與泡沫、鎖定大象與真實商機的決策地圖——這正是CRIF希望在這類研究裡提供的價值。
若您有任何問題或需要進一步了解,歡迎隨時聯繫我們。
市場研究部│李俊 協理(業界年資14年,商業數據分析師專業級證照及產業分析師技能證書,服務過超過三百家以上企業)J.Lee@crif.com 分機:668
